BUILDING ROCK SOLID PACKET CAPTURE
Hacking together a 10G packet capture system from parts is pretty easy these days, yet making that system absolutely rock solid is a completely different ball game. We`ve spent so much time fixing the 1 in 1000 type of errors which is time consuming and painful but absolutely critical to creating a rock solid packet capture system.

Back in the day when I was working on the PlayStation3 firmware, there was this strange moment of insight after watching the hardware guys do their testing / characterization. They use a completely different mind set, specifically its a statistical approach to the problem of reliability. As there are so many variables to hardware reliability that its impossible to reduce it to a set of absolutes. Using a statistical sampling process and a constrained multi-dimensional variable space, its possible with high certainty you can say the reliability with these conditions is XX.xxxxx%.
If you talk to software guys about this kind of approach, its largely wtf. I mean you have some unit and system tests, possibly an underpaid QA team or maybe bob the coder is such a hotshot testing isn't required? For some kinds of applications maybe that that's good enough but certainly not for our packet capture systems. One of the hardest things about packet capture is its a hard real-time application, meaning any system variability effects its performance. This makes real testing hard, as linux systems have a near limit less number of ways you can negatively effect the performance of an neighboring application.
"ONE OUT OF 1000 CAPTURES"
As such, we take the same numbers game approach to testing that I used on parts of the PlayStation3 firmware. Meaning 1000`s and 1000`s of back to back capture sessions, 1000`s of system reboots, Peta-bytes worth of captured data, millions to trillions of test results so we catch that one TLB shootdown, which occurs exactly when the NIC is running out of PCIe credits that causes extra pressure on the memory system. So much pressure that it feeds back into the PCIe system and the NIC has to drops a few packets.... and oh... it only happens 1 out of 1000 capture runs.. and requires a full moon and chicken blood - but this is exactly what we`re testing for.
Its this kind of testing that makes systems rock solid and dependable, and you only get that though extreme system tests. The other problem of doing this type of testing is how incredibly time consuming it is, to get an idea of the scale check out the screen shots below.
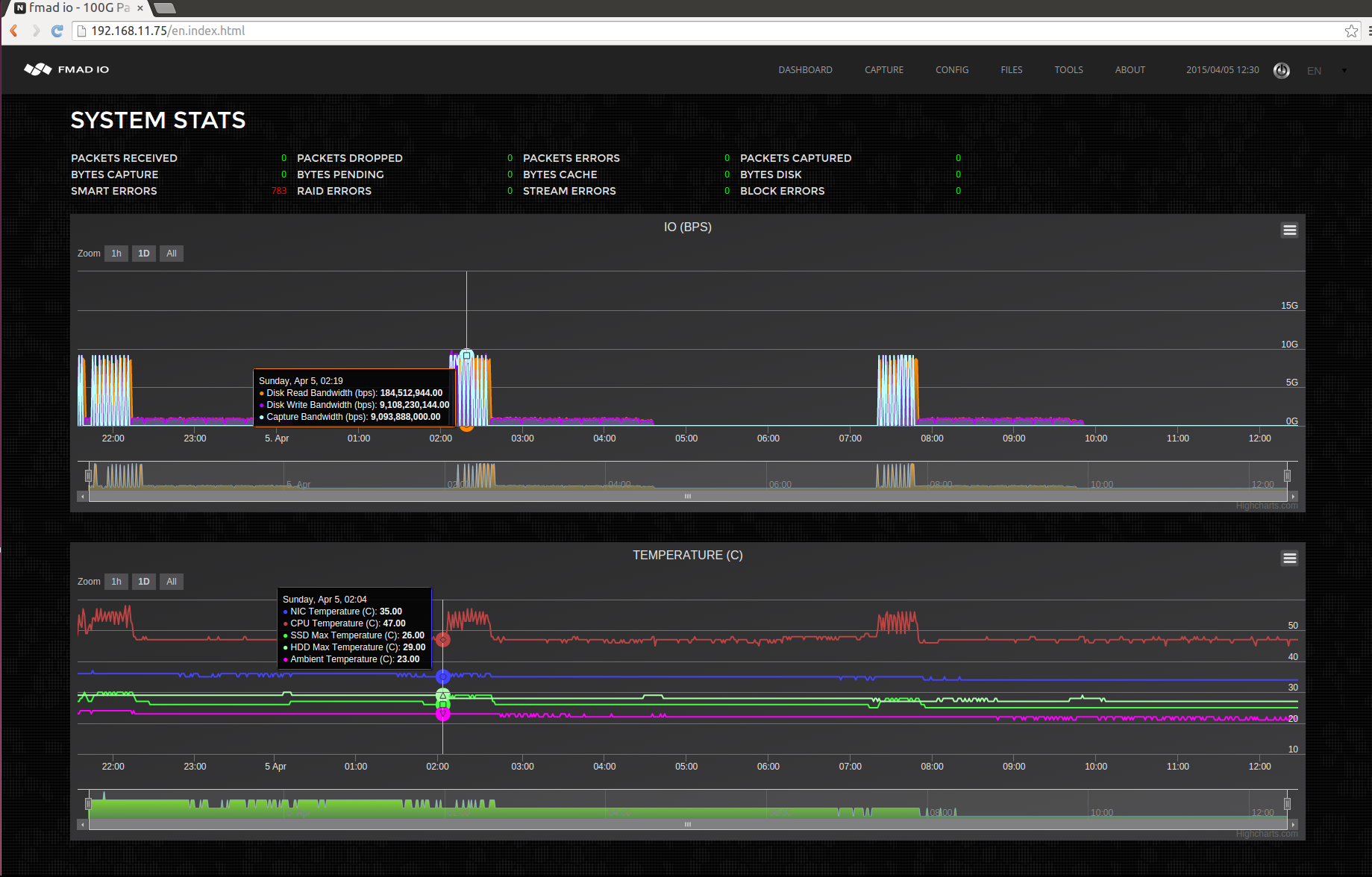
(the smart errors are due to intentionally using a faulty spinning disk for the test)
... and zooming in on one of the blocks
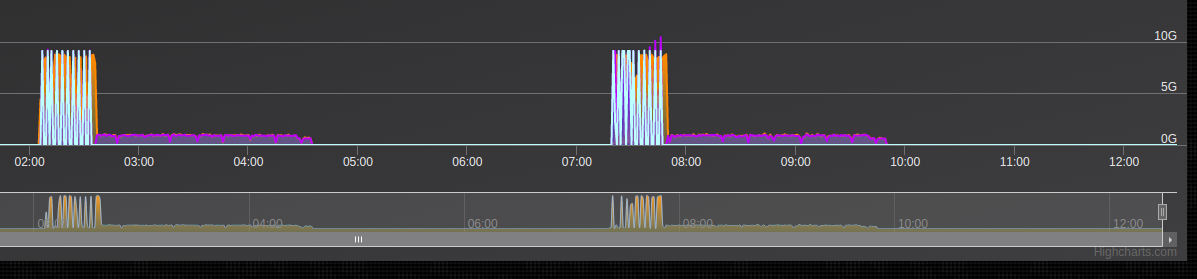
You can see the time scale, 2 cycles in 10 hours, this is one of the slowest tests. Its is doing 10 x 100G 64B line rate captures which finish quickly (aqua/orange section of the plot), followed by a complete write back into RAID5 disk (purple), and then verify the integrity of the entire 16TB array (blank section). First one starting at around 2AM and finishing a little after 7AM, making it 5hours for one run... painful but absolutely necessary.
We are working hard on testing like this to give us confidence in the systems reliability. So you get an absolutely rock solid packet capture system.