Push Compressed Realtime 1min OPRA Multicast PCAP
The OPRA market data feed is used as a benchmark for Feed handlers, Packet Capture and everything in between, primarily as the data rate and total size of the feed is larger than any other market or exchange. FMADIO Packet Capture systems, such as our FMADIO 40G Appliance, can capture and store both A and B feeds, however what good are those packets if they’re sitting statically on storage?
FMADIO has two families of Packet Capture appliances, one we refer to as “Capture”, which are cost optimised for market leading capture rates at affordable prices. The other is the “Analytics” family of appliances, with bigger CPUs and more RAM. Analytics systems are designed to run analysis and processing applications on the FMADIO appliance, either using one of our own apps, or using 3rd party and open source apps. Typically this makes data easily available for downstream systems to process either as raw PCAPs, compressed PCAPs, processed JSON or some other format.
| SKU | Capture Speed | CPU | RAM |
|---|---|---|---|
| FMADIO100-1U-ANALYTICS | 100G | 96 | 576GB |
| FMADIO40-1U-ANALYTICS | 40G | 96 | 384GB |
| FMADIO20-1U-ANALYTICS | 20G | 96 | 384GB |
| SKU | Capture Speed | CPU | RAM |
| FMADIO100-1U-CAPTURE | 100G | 32 | 64GB |
| FMADIO40-1U-CAPTURE | 40G | 32 | 64GB |
| FMADIO20-1U-CAPTURE | 20G | 32 | 32GB |
The above SKU list shows the difference between CPU and RAM, where the Analytics systems have almost 100 vCPUs and around half TB of RAM. This gives the Analytics systems a massive amount of general purpose compute for any kind of analysis and processing of packet data.
The diagram below is a general data flow for analytics processing. One key point is the Packet Analysis software retrieves data from Storage system (not transient RAM). This is important as it means the Packet Analysis software has no hard real-time processing deadlines, as it effectively has a 1TB - 300TB FIFO to work with. The analysis software can run as fast or slow as needed with no impact on the capture performance. We designed and built our own very fine grained IO architecture using a custom file system with this in mind. This enables FMADIO systems to prioritize writing packets to disk over everything else.
The net result is that the analysis software has no impact on the Capture to Disk performance, and you never drop packets.

FMADIO ANALYTICS Packet Processing Analysis
Realtime OPRA Processing
One simple but extremely useful packet processing pipeline is to Sort, Filter, Compress and Push PCAPs to downstream systems. This allows the downstream systems to work on significantly smaller and very targeted datasets, so that the downstream systems do not have to filter and grind through Terabytes of irrelevant data.
Think of the FMADIO appliance as a kind of load balancer between your Switch/TapAgg network infrastructure and downstream Compute/analysis software.
The general architecture looks like the following; this is all on a single appliance and built into every FMADIO system; only configuration is required.
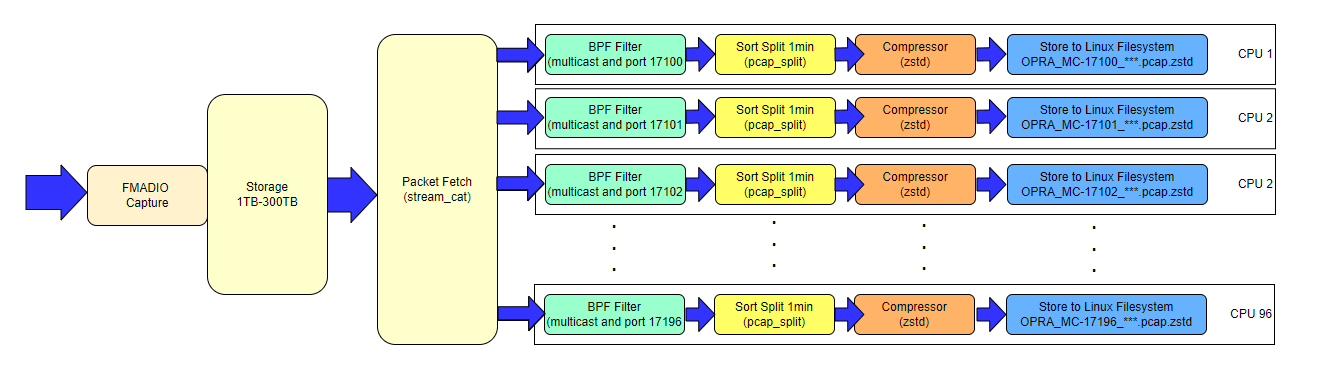
PCAP Processing Pipeline 1Min Multicast Port Compressed
In this example we will push 96 unique BPF filtered PCAPs, split into 1 minute intervals and compressed, to a downstream system via an NFS mount point. The final output looks something like the following. (NOTE: Our OPRA test data is old from 2017 thus the filenames.)
Each OPRA Multicast group is split into 1 minute intervals, filtered by multicast port and compressed using zstd…. all in near-realtime!

Example OPRA 1 Min PCAP Splits
Where does the ANALYTICS SKU fit into all of this? The computational requirements for doing this are not small. The system has to run 96 BPF Filters, 96 data splits, 96 Compression instances and egress the data down the network pipe to a remote system… Simultaneously and in parallel.
Heres a screenshot when running “htop” utility showing we are maxing out 48 CPUs, with 30 or so CPUs free for other purposes. To repeat, that’s 48 CPUs going flat out making great use of those electrons.

FMADIO PCAP Split running on 48 CPUs
Performance
In the end its all down to performance, particularly if near-realtime processing is the goal. Below is a chart showing the processing of a 100GB sample of the OPRA feed taken around 9AM EST when the market is most busy. It shows the runtime in seconds for the process on 1 , 12, 24, 48 CPUs, the scaling of how many CPUs are used is performed by running 1, 2, 4 or 8 multicast groups on the same CPU.

OPRA Filter Sort Push vs CPU Performance
The above graph shows how multiple CPUs clearly help the throughput; using 1 CPU it takes 6711sec for 100GB worth of traffic! We project that 2023 OPRA data levels will grow such that 100GB of captured data occurs in about 3.5 minutes wall time. 3.5 minutes is 214 seconds.
Using 214 sec as the max permitted processing time, we can redraw the above graph by dividing the runtime seconds by 214 to approximate how real-time the processing is. For real-time operation it needs to be < 1.0 (100%)

OPRA 2023 Datarate Relative speed
From the above its clear, a single CPU 96 Multicast groups would be 31.35x slower than wall time to process. Its not even an option even for End of Day processing.

OPRA 2023 Datarate Relative speed (minus 1 CPU graph)
Removing the 1 CPU option and we get a more reasonable looking graph. Using 48 CPUs the system can run in near-realtime with all 96 multicast groups ( 72.90% of capacity). And still have cycles left over for compression.
Anything less than 48 CPUs would be lagging at market open, but still suitable for quasi-realtime and End Of Day processing.
Compression
Compressing data for each filtered PCAP has many advantages
Less Network Traffic
Less Disk Storage
If you’re paying per gigabyte for network traffic a reduction in total bits transferred translates to real-world $$$
Same goes for storage, there is always a $/GB cost, either your own hardware/storage or storage as a service. By compressing the data x3 reduces the cost of PCAP storage by 1/3rd. That’s real dollars saved.
Below is a chart of additional CPU cost when enabling different forms of compression

PCAP Compression OPRA Multicast 1min
The only real options for realtime push with compression is ZSTD and LZ4. We used the default compression mode for ZSTD in this test; we would expect the —fast mode would have better performance.
Compression Ratio as follows
uncompressed 93.1GB
ZSTD (default) 28.6GB ( x 3.25 ratio )
GZIP (default) 31.0GB ( x 3.01 ratio)
LZ4 (default) 40.3GB ( x 2.31 ratio)
Even though FMADIO ANALYTICS SKUs are more expensive, looking at all the knock on savings in Compute, Bandwidth and Storage, the upfront cost is outweighed by the long term operational savings.
Summary
FMADIO ANALYTICS Systems can bridge the gap between the Tap Agg network infrastructure and engineers who want to consume and process that data. The additional CPU and RAM the system provides can be used in many different ways, a simple and effective use is, a wide BPF Filter, Sort by 1min , Compress with zstd, Push to an nfs share, is a great way to utilize the resources.